
In this article, we describe the block of the scheme, devoted to serving and monitoring machine learning models.
Please, find the whole scheme, which describes key MLOps processes here. The main parts of the scheme are horizontal blocks, inside of which the procedural aspects of MLOps are described. Each of them is designed to solve specific tasks within the framework of ensuring the uninterrupted operation of the company’s ML services.
ML models in production require generating predictions. However, the machine learning model itself is a file that cannot easily generate predictions. A common solution found online is for a team to use FastAPI and write a Python wrapper around the model to “retrieve predictions.”

If we add more details, there are several possible scenarios from the moment the team receives the ML model file. The team can:
- Write all the code to set up a RESTful service,
- Implement all the necessary wrapper code around it,
- Collect everything in a Docker image,
- Eventually, spin up a container from this image somewhere,
- Scale it in some way,
- Organize metrics collection,
- Configure alerts,
- Set up rules for rolling out new model versions,
- and much more.
Doing this for all models while also maintaining the code base in the future is a laborious task. To make it easier, special serving tools have emerged that have introduced three new entities into the system:
- Inference Instance/Service,
- Inference Server,
- Serving Engine.
An Inference Instance or Inference Service is a specific ML model prepared to receive requests and generate predictive responses. In essence, such an entity can be represented by a container with the necessary technical equipment for its operation in a Kubernetes cluster.
An Inference Server creates Inference Instances/Services. There are many implementations of Inference Servers, each of which can work with specific ML frameworks, converting trained models into ready-to-process input requests and generating predictions.
A Serving Engine performs the main management functions. It determines which Inference Server will be used, how many copies of the received Inference Instance need to be launched, and how to scale them.
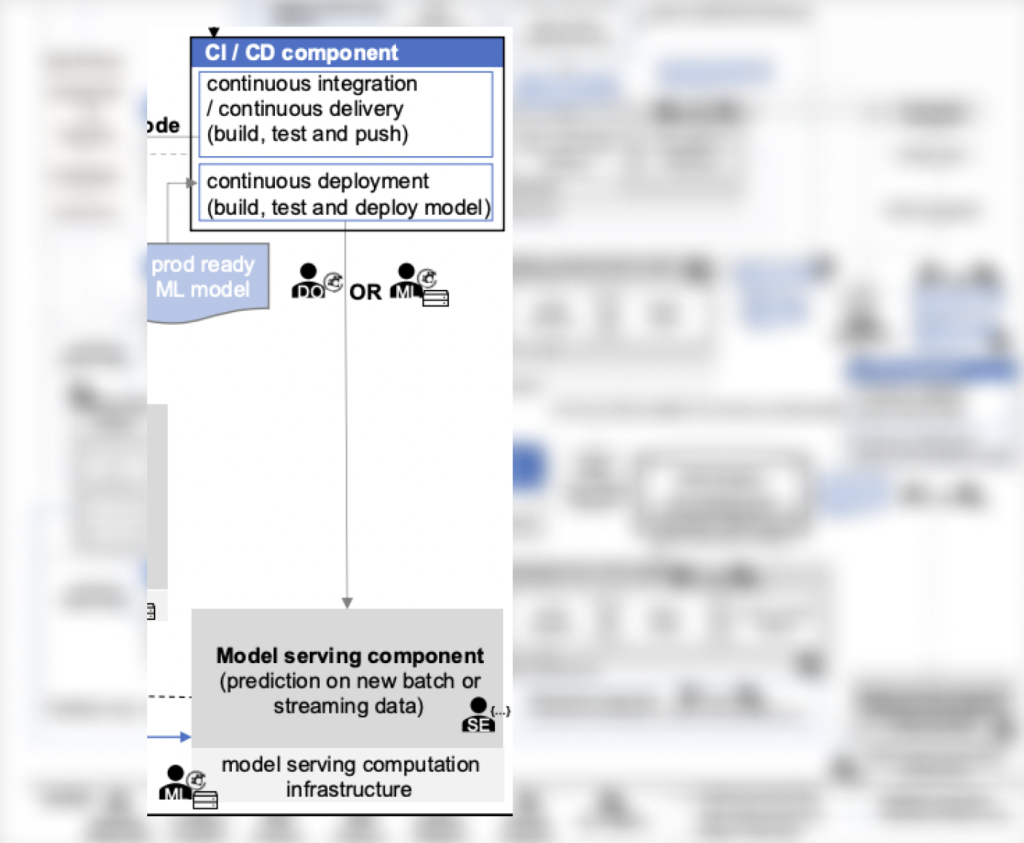
In the context of the discussed system, there is no component-level model serving detail, but there are similar aspects:
- The CI/CD component that handles the deployment of models ready for production (it can be considered one of the versions of Serving Engine), and
Model Serving, which organizes the scheme for generating predictions for ML models within the available infrastructure, both for streaming and batch scenarios (it can be considered one of the versions of Inference Server).
As an example of a completed stack for Serving, one can refer to the Seldon stack:
- Seldon Core is a Serving Engine,
- Seldon ML Server is an Inference Server, which prepares access to the model via REST or gRPC,
- Seldon ML Server Custom Runtime is an Inference Instance – an example of a wrapper for any ML model, an instance of which needs to be launched to generate predictions.
There is even a standardized protocol for implementing Serving, the support of which is de facto mandatory in all similar tools. It is called the V2 Inference Protocol and was developed by several major market players – KServe, Seldon, Nvidia Triton.
Serving vs deploy
In various sources, one can come across the mention of “Serving and Deploy” tools as a whole. However, it is important to understand the difference in their purpose. This is a debatable issue, but in this article, it will be as follows:
Serving – is about creating a model API and the ability to get predictions from it, i.e. ultimately – obtaining a single service instance with a model inside.
Deploy – is about distributing the service instance in the required quantity to process incoming requests (you can imagine a replica set in Kubernetes deployment).
There are many strategies for deploying models, but this is not ML-specific. The paid version of Seldon, by the way, supports several of these strategies, so you can simply choose this stack and enjoy how everything works by itself.
It is important not to forget that model performance metrics must be tracked, otherwise, it will not be possible to solve emerging problems in a timely manner. How to track metrics is a big question. The company Arize AI has built a whole business on this, but Grafana with VictoriaMetrics has not been canceled either.
💡 You might be also interested in our article ‘Key MLOps processes (part 3): Automated machine learning workflow’ → https://hystax.com/key-mlops-processes-part-3-automated-machine-learning-workflow.
✔️ OptScale, a FinOps & MLOps open source platform, which helps companies optimize cloud costs and bring more cloud usage transparency, is fully available under Apache 2.0 on GitHub → https://github.com/hystax/optscale.