
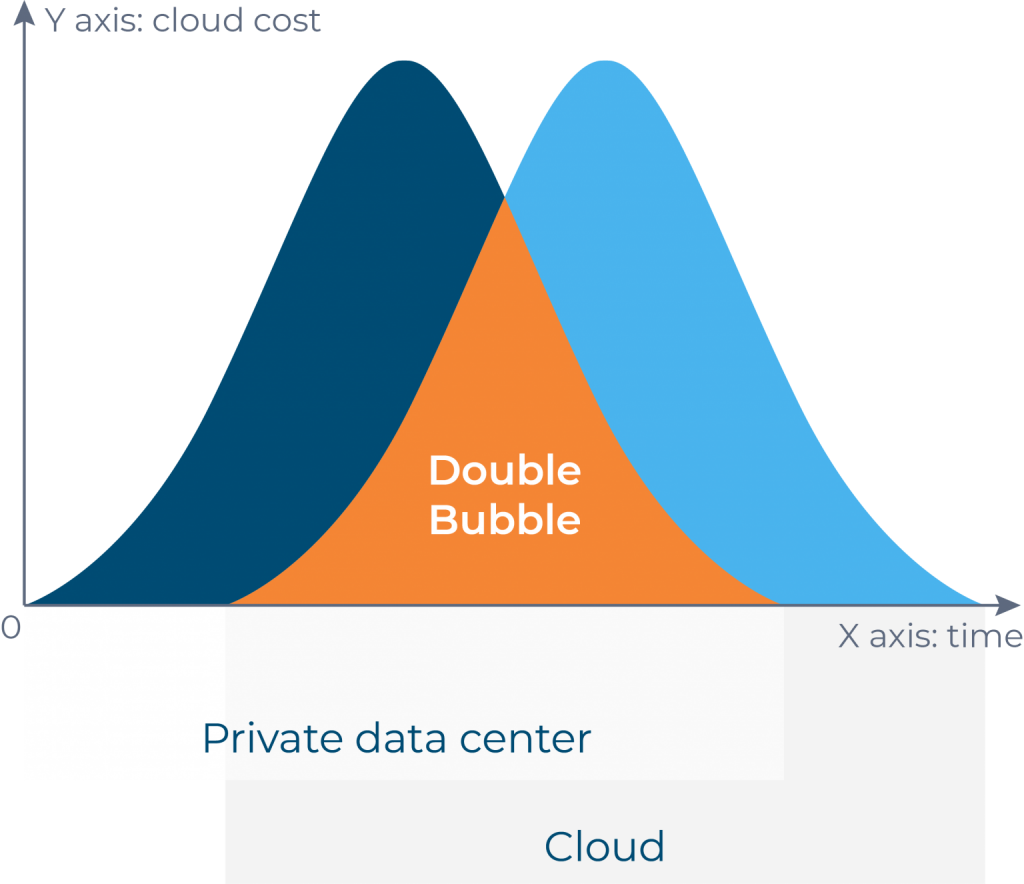
I’ve recently read a nice article by Intuit engineering team where they mentioned an interesting topic – double bubble. In terms of clouds it’s a state during cloud migration or digital transformation when you pay for both clouds, source and target sites. Let’s discuss how common it is.
A standard cloud migration project consists of a defined set of steps:
1. IT justification and proving a business need. The justification can be to avoid vendor lock-in, datacenter lease hardware or software license renewal cycle, scaling velocity, TCO or public cloud discount etc. Usually, when there is a clear justification, it’s not an issue to prove the business need.
2. Project scope definition. At this step a responsible person (project manager) and specific applications/resources are defined.
3. Cloud migration phase.
4. Post-mortem.
We’ll be talking only about p. 2 and 3 for now. It’s normal during the migration process there are times when you have resources running on both, source and target cloud. Some of the resources may be already migrated, some still can be in a queue or even not defined for migration and still running on a source cloud. But there is an interesting case when you migrate some resources (in some cases hundreds or thousands of machines) and need to pay for them twice.
Achieving effective cost management is all about optimization and tracking. With a set of policies, principles and processes in place, businesses can appease stakeholders and ensure their cloud spends remain under control. If your cloud spend bill comes as a surprise each time you receive it, you’re simply not taking advantage of all of the cost governance tools out there.
When companies define what to move to a cloud, usually they think in categories of applications, departments or entire resources. Experienced migration consultants or vendors will always advise to split resources into chunks of 30–50 VMs and migrate by phases. From one side it reduces risk, from the other side it exactly helps to blow off the bubble. Ideally, a single application should be in one chunk. In that case you can migrate and test the whole granular part of your system and avoid data locality issues. Remember that cross-region and outbound cloud traffic is not for free and is pretty expensive. It’s better to think about that before you receive your first cloud bill.
The root cause of the bubble is in ‘replication -> testing’ -> cutover scope. When you migrate some chunk, it takes some time to replicate data, define how you’ll grab increments (better in an automated way), how to test the chunk on a target cloud and schedule a maintenance window to execute the cutover. And those 3 phases form the bubble. You store the data in block devices or an object storage, run VMs on a target cloud and pay for compute. In the majority of the cases, test migrations can run for 1–3 weeks (can be even more) till a team that owns the migrated application validates that all is fine with it on a target cloud and there are no performance degradation or other issues. And if you migrate multiple chunks in parallel the bubble will grow.
So how to avoid the bubble…
1. First of all, identify your migration pace. Be very frank with yourself, it’s exactly how to learn a new skill – very slow in the beginning and much better after a few iterations.
2. Define a queue of applications/chunks. Put it into your migration project calendar.
3. Figure out a way how to replicate VMs without downtime and without re-replicating them all the time. There are dozens of tools doing that and it saves your time and money as you pay less for storage.
4. Communicate with teams owning the chunks or apps. Define acceptance criteria and cutover process with them, the earlier they start thinking about that, the more prepared they will be when the time comes. Define time slots when they need to test the migration. This is the most important step as the testing blows the bubble and usually teams don’t have any idea how to test applications, what the components are and who owns individual machines.
5. Define the waiting period – how long you wait until you remove migrated VMs from the source environment. Don’t forget that on one side you need some backup plan if something goes wrong with VMs and apps on a target cloud and, on the other side, you still pay (directly or indirectly) for the machines on a source side.
6. Shutdown the tests as soon as you see that the team is not prepared or it’s not their priority right. If they are not motivated, they will just waste time (equals to money in public clouds) or, even worse, make a decision (accept or reject) based on some odd criteria and either, proceed to use the machines on a source cloud or will figure out that were issues when source VMs would have been already removed. Reiterate with their manager or upper management to adjust both teams’ priorities.
7. If tests pass, proceed with the cutover. Remove all snapshots and test migrations for the migrated applications. Don’t forget to start the clock of waiting time for them.
8. Revisit your pace estimates and adjust your schedule.
You’ll have some sort of double bubble in any migration project but you can control how big it will be by proper planning and communication with applications and VMs owners. Only brave people migrate entire infrastructure in a single run, smart people plan and do it in chunks and phases.

Nick Smirnov, Digital transformation & FinOps enthusiast and visionary, CEO at Hystax
