

The main parts of the scheme, which describes key MLOps processes, are horizontal blocks, inside of which the procedural aspects of MLOps are described (they are assigned letters A, B, C, D). Each of them is designed to solve specific tasks within the framework of ensuring the uninterrupted operation of the company’s ML services. To understand the scheme better, it would be good to start with Experimentation.
Experimentation, or the process of conducting experiments
If a company has ML services, then there are employees working in Jupyter. In many companies, all ML development processes are concentrated on this tool. This is where most of the tasks begin, for which it is necessary to implement MLOps practices.
For example, Company A has a need to automate part of a process using machine learning (let’s say the relevant department and specialists are available). It is unlikely that the solution to the task is known in advance. Therefore, the developers need to study the task and test possible ways to implement it.
For this purpose, an ML engineer/ML developer writes code for various task implementations and evaluates the obtained results against the target metrics. This is almost always done in Jupyter Lab. In this form, a lot of important information needs to be recorded manually, and then the implementations need to be compared with each other.
This activity is called experimentation. Its essence is to obtain a working ML model that can be used to solve corresponding tasks in the future.
The block labeled “C” in the diagram describes the process of conducting ML experiments.
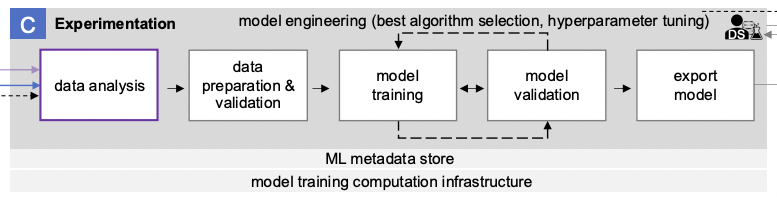
It includes the following stages:
- Data analysis
- Data preparation and validation
- Model training
- Model validation
- Model export
Data analysis
Many decisions in ML development are based on the analysis of the data available in the company (not necessarily big data). It is impossible to train a model with target quality metrics on low-quality data or data that does not exist. Therefore, it is important to understand what data we have and what we can do with it. To do this, for example, we can conduct an ad-hoc investigation using Jupyter or Superset, or a standard Exploratory Data Analysis (EDA).
A better understanding of the data can be obtained in conjunction with semantic and structural analysis. However, data preparation is not always within the project team’s sphere of influence – in such cases, additional difficulties are ensured. Sometimes at this stage, it becomes clear that it does not make sense to continue developing the project because the data is unsuitable for work.
Data analysis
Once confidence in the available data is established, it is necessary to consider the rules for their preprocessing. Even if there is a large set of suitable data, there is no guarantee that it does not contain missing values, distorted values, etc. This is where the term “input data quality” and the well-known phrase “Garbage in – garbage out” come into play. No matter how good the model used is, it will give low results on low-quality data. In practice, a lot of project resources are spent on forming a high-quality dataset.
ML model training and validation
After the previous stage, it makes sense to take into account the metrics of the trainable model when conducting experiments. In the context of the considered block, the experiment consists of training and validating the ML model. In fact, the experiment consists of the classic scheme of training the desired version of the model with the selected set of hyperparameters on the prepared dataset. To do this, the dataset itself is divided into training, testing, and validation sets. The optimal set of hyperparameters is selected for the first two, while the final check is performed on the validation set to confirm that the model trained on the selected set of hyperparameters behaves adequately on unknown data that did not participate in the process of selecting hyperparameters and training. This article gives more detail on the described process.
Saving code and hyperparameters in the repository
If the training model metrics are considered good, then the model code and selected parameters are saved in the corporate repository.
The key goal of the experimentation process is model engineering, which implies the selection of the best algorithm for implementing the task (best algorithm selection) and the selection of the best model hyperparameters (hyperparameter tuning).
The complexity of conducting experiments is that the developer needs to test a huge number of combinations of model parameters. And this is not to mention the various options for using mathematical tools. In general, this is not easy. So, what should you do if, during the parameter combinations, the desired metrics cannot be achieved?
💡 You might be also interested in our article ‘What are the main challenges of the MLOps process?’
Discover the challenges of the MLOps process, such as data, models, infrastructure, and people/processes, and explore potential solutions to overcome them → https://finopsinpractice.org/what-are-the-main-challenges-of-the-mlops-process.
✔️ OptScale, a FinOps & MLOps open source platform, which helps companies optimize cloud costs and bring more cloud usage transparency, is fully available under Apache 2.0 on GitHub → https://github.com/hystax/optscale.
